

Other related sites:
Systems Tested.
CPU Benchmarking
Project
|
||||||||
|
CPU |
Clk |
Run Time |
Efficiency |
Equivalent Clock Speed for a |
|
|||
|
P3 Celeron |
Pentum |
386 |
||||||
|
P4 |
3800 |
1.27 |
71.6% |
2720.20 |
4999.61 |
25115.11 |
WinXP - Cygwin |
|
|
P4 |
3000 |
1.57 |
73.7% |
2211.43 |
4064.52 |
20417.76 |
Linux 2..6.11.4 |
|
|
P4 |
2266 |
2.29 |
66.7% |
1510.47 |
2776.18 |
13945.90 |
FBSD 4.4 |
|
|
P4 |
1800 |
4.23 |
45.5% |
819.33 |
1505.89 |
7564.73 |
Win 2K - Cygwin |
|
|
P3 |
1150 |
3.06 |
98.4% |
1131.37 |
2079.41 |
10445.75 |
OBSD 3.1 |
|
|
VIA Eden |
1000 |
8.07 |
42.9% |
429.26 |
788.96 |
3963.30 |
Win 2K - Cygwin |
|
|
P3 |
866 |
3.99 |
100.2% |
867.67 |
1594.74 |
8011.03 |
Slackware 2.95.3 |
|
|
P3 |
866 |
4.37 |
91.5% |
792.40 |
1456.40 |
7316.09 |
RedHat 2.96 |
|
|
Celeron |
766 |
4.67 |
96.8% |
741.49 |
1362.82 |
6846.01 |
FBSD 4.6.2 |
|
|
Celeron |
766 |
5.09 |
88.9% |
680.56 |
1250.84 |
6283.47 |
Win 2K - Cygwin |
|
|
AMD-K7 |
550 |
7.28 |
86.5% |
475.55 |
874.04 |
4390.66 |
RedHad |
|
|
AMD-K7 |
550 |
7.28 |
86.5% |
475.68 |
874.28 |
4391.87 |
Slackware |
|
|
Celeron |
533 |
6.72 |
96.7% |
515.41 |
947.30 |
4758.67 |
FBSD 4.6.2 |
|
|
Xeon PII |
450 |
7.70 |
100.0% |
449.90 |
826.90 |
4153.87 |
FBSD 3.0 |
|
|
AMD-K6 |
450 |
8.47 |
90.9% |
408.74 |
751.24 |
3773.79 |
FBSD 2.2.7 |
|
|
AMD-K6 |
450 |
8.50 |
90.5% |
407.25 |
748.50 |
3760.03 |
FBSD 2.2.7 |
|
|
AMD-K6 |
450 |
8.49 |
90.6% |
407.63 |
749.21 |
3763.57 |
FBSD 3.2 |
|
|
AMD-K6 |
450 |
9.12 |
84.4% |
379.77 |
698.00 |
3506.36 |
Linux 2..4.19ac2 |
|
|
Xeon PII |
400 |
8.69 |
99.6% |
398.39 |
732.22 |
3678.25 |
FSBD |
|
|
AMD-K6 |
400 |
9.19 |
94.2% |
376.67 |
692.31 |
3477.75 |
FSBD |
|
|
AMD-K6 |
350 |
10.31 |
95.9% |
335.73 |
617.05 |
3099.69 |
FSBD |
|
|
Intel ? |
350 |
10.25 |
96.5% |
337.82 |
620.90 |
3119.05 |
FBSD 4.1.1 |
|
|
Intel PII |
333 |
10.75 |
96.8% |
322.20 |
592.18 |
2974.78 |
FBSD 4.6.2 |
|
|
AMD-K6 |
300 |
12.64 |
91.3% |
273.85 |
503.32 |
2528.40 |
FSBD |
|
|
Cyrix GXm |
233 |
32.31 |
46.0% |
107.16 |
196.95 |
989.35 |
FSBD |
|
|
Cyrix
586? |
200 |
32.55 |
53.2% |
106.36 |
195.48 |
982.00 |
FBSD 2.2.7 |
|
|
Pentium |
166 |
38.21 |
54.6% |
90.60 |
166.53 |
836.53 |
FBSD 2.1.0 |
|
|
IBM Pwr 2 |
135 |
38.61 |
66.4% |
89.67 |
164.80 |
827.87 |
AIX XLC -O2 |
|
|
IBM Pwr 2 |
135 |
47.55 |
53.9% |
72.81 |
133.82 |
672.22 |
AIX gcc -O3 |
|
|
Pentium |
133 |
47.90 |
54.4% |
72.28 |
132.84 |
667.32 |
FSBD |
|
|
Pentium |
120 |
52.92 |
54.5% |
65.42 |
120.24 |
604.01 |
FSBD |
|
|
Pentium |
120 |
53.15 |
54.3% |
65.14 |
119.72 |
601.39 |
FSBD |
|
|
486DX2 |
66 |
115.46 |
45.4% |
29.98 |
55.11 |
276.84 |
FBSD 2.2.7 |
|
|
486DX |
66 |
153.38 |
34.2% |
22.57 |
41.49 |
208.40 |
FBSD 3.1 |
|
|
486DX |
66 |
153.45 |
34.2% |
22.56 |
41.47 |
208.30 |
FBSD 3.1 |
|
|
486DX |
66 |
154.57 |
33.9% |
22.40 |
41.17 |
206.79 |
FBSD 3.1 |
|
|
486 |
33 |
230.42 |
45.5% |
15.02 |
27.61 |
138.72 |
FBSD 3.1 |
|
|
386DX |
40 |
537.78 |
16.1% |
6.44 |
11.83 |
59.44 |
FBSD 3.1 |
|
|
386 |
40 |
784.51 |
11.0% |
4.41 |
8.11 |
40.74 |
FBSD 3.1 |
|
|
386 |
16 |
1997.80 |
10.8% |
1.73 |
3.19 |
16.00 |
FBSD 3.1 |
|
Efficiency
Efficiency is computed as N / (MHz * time) where N = (MHz * time) for the Xeon
PII 450 MHz CPU. This is to normalize the data to a frame of reference.
This give a measure of how much code is ran per CPU cycle. These numbers are relative to the best performing CPU that I had tested, PII Xeon.
The reason to compute efficiency like this assumes doubling the CPU clock will halve the execution time of a program.
For Example: A program running for 2 minutes on a 100 MHz system should take 1 minute on a equivalent 200 MHz system.
Note: Overall CPU performance would be Efficiency * Speed.
Observations
Notice how the efficiency has been steadily increasing
over time except for the P4, which drops drastically by 1/3!
This would imply a 600 MHz P2 Xeon and a 900MHz P4 would run about the same!
Yet the Pentium 4 is still the Equivalent to a 14 Gigahertz i386 CPU
These measurements were done using the using the Non-optimized executables. To increase the precision of the measurements on the faster systems the program was executed 10 to 100 times in a row with a simple shell script. Measurements were done in bourn Shell “/bin/sh” using “time”.
Over the years I have benchmarked a number of different
CPU’s. The program used for the benchmark just does simple bit shifting, and,
or and comparisons and was used for brute force testing of Hamming distances in
block codes. The Program is called ecc4.c, it was not deliberately chosen for
these benchmarks, I was just taking a very long time to run and over the course
of several years its performance was tracked and carefully studied and it turns
out to be very well behaved and good for benchmarking.
These numbers do not take into account Floating point or even integer math nor
the MMX or other extended instructions or optimizations. They should provide a
basic look at the performance of the internal instruction core of the CPU,
since this code should easily fit entirely in cache
.
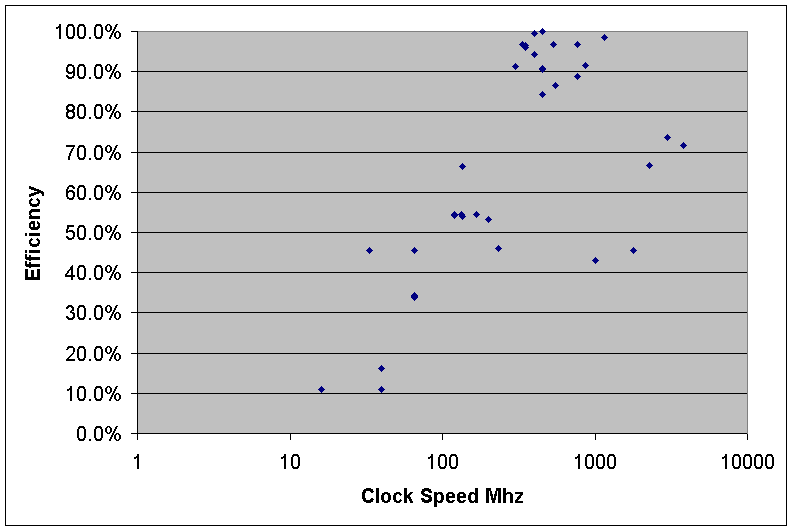
This is the code execution efficiency vs. CPU speed, As CPU’s
became faster they also became better at running code so there was a greater
speed increase then just the MHz clock speed.
Again Notice the P4 on the far right, even though it’s clock speeds are higher,
it’s runs code less efficiently, this give a lower relative performance.
Copyright © 1998-2005 John
L. Sokol
http://www.dnull.com/~sokol